This post intends to share my experience in defining configuration for software products that require a large number of configurations. There are applications such as message brokers, ESBs, POS systems, etc that require multiple configurations to make that product works. At this point, the user may lose in a sea of configurations if the developer does not correctly place those configurations in proper order and if documentation is completed. How could you arrange your configuration such that the user can easily work with it?
There could be different things that may become reason, software to become harder to configure. Bad user experience in configuring software means your product loses customer impression. The entry point for your software application most probably maybe doing configuration. If the user thinks configuring is hard at this point, he may give up the whole product.
Early days developer used simple config formats such as properties file to configure products. Property files are simple yet powerful config formats that even use today. This type of config file containing key-value pairs to define configs. When the product is running, it reads configs from the property file and adapts according to that.
Later, developers move into data formats such as XML and JSON to config products. These configs are both human and machine-readable. This type of config can represent more complex and organized configs. Other than defining just key and value, this format can be used to store hierarchical data as well.
But later developers created more modern config formats such as YAML and TOML. This configuration format also can be used to define more complex data structures while it is highly human-readable than XML and JSON format. These days people have a huge trend of using YAML and TOML format to configure their products.
Configuration module steps and feature
Configuration module can have different features to make configuration much more easily for the user rather than just having a key-value declaration.
- References
In some configuration requirements, the user may need to reuse already defined configurations in another place as well. Therefore you can add a commonplace to keep the value and use the relevant key in the place you need to access the reference.
- Defaults
Configs have a default value when the user does not define the actual configs. When the user first downloads the product, they might not have an in-depth idea about the product features and configs. Having default makes the first time user experience much simpler for the user.
- Validation
Configuration should be validated before it loaded into the system. As an example, if some config is to collect email addresses, it should have some particular format. This can be simply validated with regular expressions.
- Inferring
Not all configurations should be defined by the user. Some information can be calculated and re-use it. For example, the URL can have a hostname, port, and resource location. You can reuse these components to rebuild another URL as well if you have a hostname and port collected separately.
- Support units
In most of the configuration file formats asking the user to provide the value with the given unit. For example, timeout value expecting from milliseconds. On the other hand, you can have an abstract system that can read configs along with the unit name. For the same previous example, you can define timeout as “100ms” on the configuration file.
- Keeping secrets
You can keep the password as plain text on the config file as it reveals to someone who has access to the infrastructure. Therefore password should be kept in an encrypted format on the config file and the system should decrypt the encrypted entity and use it.
Why configuring a product becomes harder with time?
The software does not mean to keep as it is after it developed. It getting change as requirements getting more and more advanced. Due to this reason, developers have to introduce more and more configs into their product in order to make it more configurable for each of the users. If the software process is not properly maintained, then the end-user may be ended up in a mess of configurations.
The software development process is long term and it may take a few years to release production-grade end output. Once it lives, it keeps evolving. In this scenario, the developer may add different types of features into the product that use different libraries. Libraries might need to config with different configuration files. For example, if you need to add logging capability to your java program, you may use log4j as your logging framework. It needs a property file that defines logging levels and rules. On the other hand, you may need to add a message builder such as Apache Axis. This library read configurations from the XML config file. Did you see the problem? There are a few different config files with different formats. This scenario is valid if the user already familiar with log4j and Apache Axis. But if the user is new to those technologies, then the user needs to learn both property files and XML file syntax.
Another problem that may cause inconsistent configuration is that poor software management. From the start of the software development process, architecture needs to follow a common standard to define configs. This standard should be defined in the planning phase of the software development process. All changes to config should be properly review since config changes are permanent for a major release and changing config later costs a lot.
Some configs might not get documented properly due to poor software management processes. Some configs might have default value even those configs not define on the config file. This can be known as ghost configs. Tracking all available configs at a later point becomes harder if you have ghost configs and you didn’t document those either.
So, How to create a project which has a large number of configuration files?
With the old school waterfall model, you can collect all of the requirements and define the configurations at the planing process. But software developers nowadays no longer using the waterfall model and moving on with the agile development method. Since you don’t have all the requirements at the initial phase you need to plan more about your configuration consistency.
Avoid using XML and JSON as configuration format. Those formats are intended to use as both machine and human-readable. But there are file formats such as Properties, YAML, TOML that specifically written to configure software products. If you are looking for a simple product that has simple configs, the go for Properties file. You can use YAML and TOML to define more complex configurations such as hierarchical config structures.
Collect all current requirements that you supposed to implement. This information is valuable to create a consistent config that does not change over time. Discuss the future plans and feature that willing to introduce. Make slots for those upcoming configurations as well. Based on the requirements categories the configs and make a rough template about config format. Also, limit the number of configs in you produce as much as possible.
Select a config file format that can be easily used by the end-user. While collecting the user persona collect the format of the config that they are already using. For example, if the end-user using Kubernetes with your product, they might be familiar with YAML format.
Avoid having multiple configuration files in your product. Do not include multiple configuration files that have different config formats. I would suggest having a single file to configure a single product. If you need to add libraries that read configs other than the existing config file, try to add those configs as well into the single config file. The decision of having a separate file for a given library is valid if you can find out the user already familiar with that config format. This decision should be taken by analysing end-user persona.
What should I do if I have a software with configuration mess already?
The simplest solution is to create a single object that can be able to hold all configs and replace it with all of the places where configuration reading. This becomes might hard if you are using libraries that used to read different configuration file formats.
This is the same problem that we have faced that the software had lots of different configurations but the reading configuration has no well-defined software architecture. The different module has different methods of reading configuration with the different file format. Therefore finding all of these configurations is harder and it might make the whole system fragile if configuration missed. Therefore, configuration keep as it is and added another process to read configurations from a single file and replace existing files before starting the system. Here, you can select any file format with your desire and read configuration from there. Then collected configurations mapped with a pre-given template and generate required config files.
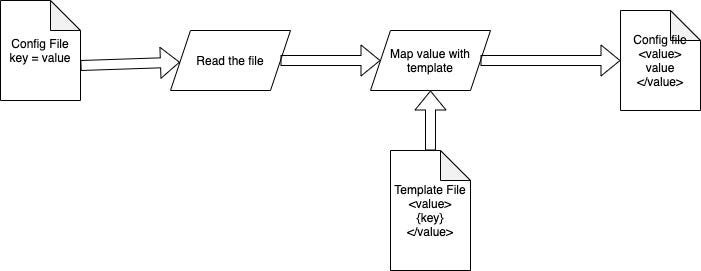
This system has the downside of having the overhead of converting the configuration file format. This might have a significant impact if you have a product that requires less startup time. Therefore you need to take the decision to reformat the code and natively support configuration or having a template engine to generate config files.
This type of solution already provided by configuration management tools such as Puppet. You can use the puppet template to create the template and use the Puppet master to configure the product as you wish. If the end-user does not use Puppet, then you need to think a way of giving your own solution. On the other hand, you need to think about a person who already uses Puppet has additional overhead if you provide an inbuilt config generator.
Conclusion
Define configuration is a crucial point of the software product since it directly affecting the user experience. Configuration should be organised in the way that a user can easily configure the product and use it. Developers need to follow proper development methodology and plan how configs should be organised. Config is an important part of the software development process since changing syntax make a bad impact on the users. Therefore always think about the upcoming feature and design the system such that it can adopt later.
Comments
Post a Comment