Handling large software which has multiple services is a tedious, time-consuming task for DevOps engineer. Microservices comes into the rescue DevOps engineers from all these complicated deployment processes. Simply, each microservice in the system has it own responsibility to handle one specific task. The container can be used to deploy each of these micro-tasks as a unit of service. If you are not that familiar with Containers, read this article to get to know about Docker, Which is the most popular and widely used container technology to deploy microservices.
As I described early, we can use single container to deploy a single service and container contain all required configurations and dependencies. Single service always faces a common problem of a single point of failure. In order to avoid single point failure, we need to set up another service such that if one service is getting down, next available service takes that load and continue to provide the service. Another requirement to have multiple containers for the same service is that, distributing the load between the services. This can be achieved by connecting multiple services through a load balancer. To maintain multiple containers which have multiple services with service replication is not that easy task to handle manually. Kubernetes used to handle all of these complexities for you. Kubernetes provide multiple features so that you can easily maintain multiple containers which known as Container orchestration.
What Kubernetes do?
Imagine you have an application which has multiple services and each of these services configured inside a container. Let assume these two services as Service A and Service B. Also, Service A use Service B to get done some works. So, we can represent service dependency as follows.

When high availability required, then we need to scale the system so that each service have a copy of its own and run these copy in another node( separate physical/ virtual machine).
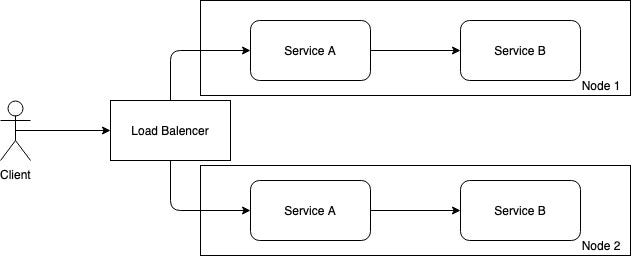
Here, load balancer used to distribute the load between servers. In this system, single point failure handled by routing traffic to other node if one node is getting down.
In lager system which has lots of nodes and services, hardware utilization may be not efficient since each of service requires different hardware requirements. Therefore hardwiring services into a specific node is not that efficient. Kubernetes provide an elegant way to solve this resource utilization issues by orchestrating container services in multiple nodes.
Kubernetes cluster maintains by the master which include scheduling applications, maintaining applications’ desired state, scaling applications, and rolling out new updates. A node is a VM or a physical computer that serves as a worker machine in a Kubernetes cluster. Node and master communicate with each other through the Kubernetes API. A Kubernetes pod is a group of containers that are deployed together on the same host.
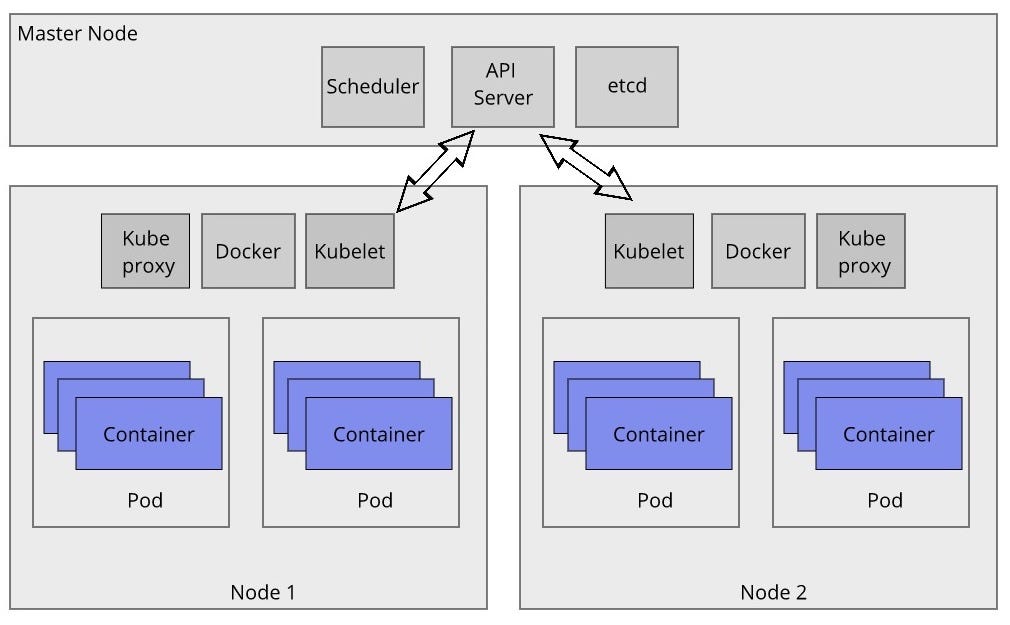
Pod
A pod is a collection of containers and the unit of deployment in Kubernetes cluster. Each of the pod having its own IP address. Which means that, each containers in the same pod have same IP address so that they can find each other with localhost.
Services
Since pods are dynamically changing, it is hard to reference individual pod. Services providing an abstraction over Pods and provide an addressable method of communicating with pods.
Ingress
Most of the time pods and services are encapsulated in inside the Kubernetes cluster so that external client cannot call these servers. An Ingress is a collection of rules that allow inbound connections to reach the cluster services.
Docker
A Docker Daemon is running in each node to pull images from the Docker registry and runt it.
Kubelet
Kubelet is the node agent that runs periodically to checks the health of the containers in a pods. API server sends instruction that required to run containers and kubelet make sure containers in desired state.
Kube-proxy
Kube-proxy distribute the load to the pods. Load distribution based on either iptable rules or round robin method.
Deployment
The deployment is what you use to describes your desired state to Kubernetes.
Features of Kubernetes
Kubernetes provide multiple features so that application deployer can easily deploy and maintain the whole system.
- Control replication
This component allows maintaining the number of replicated pods that need to keep in Kubernetes cluster.
- Resource Monitoring
Health and the performance of the cluster can be measure by using add ons such as Heapster. This will collect the metrics from the cluster and save stats in InfluxDB. Data can be visualized by using Grafana which is ideal UI to analyze these data.
- Horizontal auto scaling
Heapster data also useful when scaling the system when high load comes into the system. Number of pods can be increase or decrease according the load of the system.
- Collecting logs
Collecting log is important to check the status of the containers. Fluentd used along with Elastic Search and Kibana to read the logs from the containers.
See you in next article to get hands-on experience of Kubernetes. Cheers :).
Your blog is in a convincing manner, thanks for sharing such an information with lots of your effort and time
ReplyDeletekubernetes online training
kubernetes online course
kubernetes training
kubernetes course
kubernetes certification training